Ishaan Mehta
$ cat ~/projects/bl
Programming langugaes are cool. I use one almost every day to make cool things, and yet somehow I feel like I've never taken the time to actually learn how they work. But studying is boring and in my opinon the only real way to learn something is to do it until it clicks, so away we go on another coding adventure to make a programming language
Vocab
Real quickly before we get started, I wanted to drop this list of words I'm going to use and what they mean/do so that confusion can be avoided later on
Token: Kinda like a word, except it has extra data identifiying what it means in our language attached to it
Lexer: The thing that turns our text into smaller tokens
Expression: A step up from a token, kinda like a sentence. Think 1+1 or print('Hello World')
Parser: The thing that turns our tokens into expressions
Interpreter: The thing that processes each expression, basically the thing that runs the code
Tokenizer? I barely know her
To get started there are 2 rules you need to understand.
1. Words are made up of letters.
2. Words get seperated by not letters.
It sounds silly, because of course words are made of letters and how else could they be seperated if not by everything that isn't a letter. But that's truly all you need to remember to make a programming language.
The lexer starts out pretty simple: it takes in an array of every single character in the code file, then it goes through and follows those rules from earlier to split the characters into tokens. Let's start out simple with a lexer that turns text into either words or numbers
That looks like a lot of code for seperating numbers from words, but once you get a feel for how it works it's actually fairly simple.
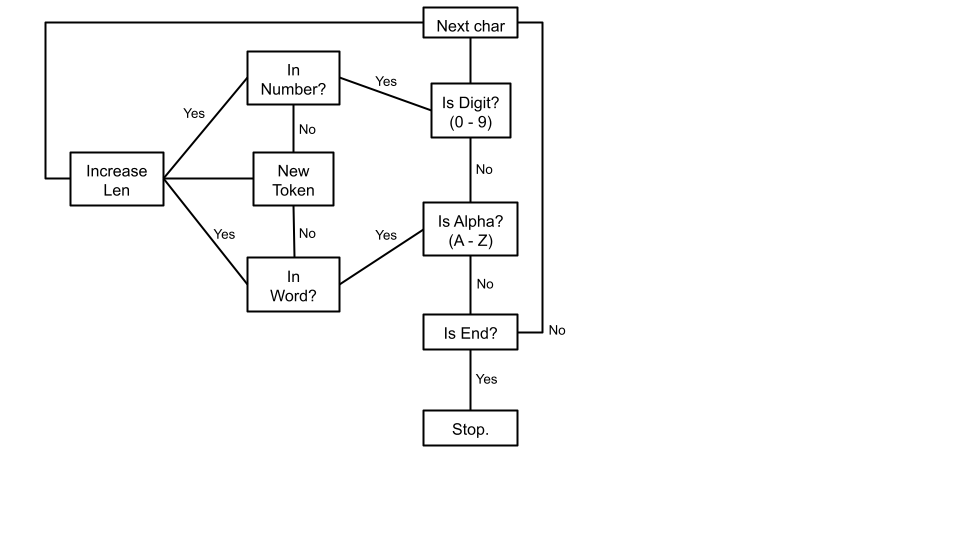
The beginning bits (from lines 2 - 5), I'm just creating a few variables to help us keep track of where we are in the file. The start variable I created is simply a pointer to somewhere within the buffer, and I later shift it forward to match where the start of our current token is. The len variable is similar, tracking the length of the current token's string. Finally the current_type token uses the following custom enum, and keeps track of whether or not we're even in a token, noting which type if we are within one.
After that I just looped through the entire buffer, using the C standard functions isdigit and isalpha to check whether or not the current character is a number (0-9) or a letter (a-z).
The checks made on line 8 and line 17 are both to see if we're already in a token, since if we are we have to branch differently from if we aren't. Below is a flowchart describing the control path of the tokenization process